Scenario
Consider
following situations
- DTP load for DSO is running more than its due time i.e. (taking more time to load data) and hence stays in yellow state for a long time and you want to stop the load to the DSO by changing the status of the loading request from yellow to red manually, but you deleted the ongoing background job for the DTP load.
- A master data load through DTP failed as the background job for DTP failed with a short dump and you want to start a new DTP load but you cannot as there is a message saying “The old request is still running”. You cannot change the status for the old request to red or green as there is message “QM-action not allowed for master data”. You cannot delete the old request due to the message “Request cannot be locked for delete”.
Solution
When old request in Scenario 1 & 2 is in yellow status and you are not able to change / delete the request, it’s actually in a pseudo status. This request sits in table RSBKREQUEST with processing type as 5 in data elements USTATE, TSTATE and this 5 is actually "Active" status which is obviously wrong.One of the possible solutions is to ask a basis person to change the status to 3 in both USTATE and TSTATE and then it allows reloading the data. Once the data is successfully loaded, you can delete the previous bad request even though it is still in yellow. Once the request is deleted, the request status gets updated as "4" in table RSBKREQUEST.
There
is one more alternative solution, wherein you can manually change the status of
the old request to red or green by using the function module RSBM_GUI_CHANGE_USTATE.
Following
are the steps to change the QM Status of a yellow request to red/green by
using RSBM_GUI_CHANGE_USTATE
1.
Select Request Id from target.

2. Go to SE37 and execute the function module RSBM_GUI_CHANGE_USTATE.

3. Enter Request Id here and execute it.

4. Then change the status of the request to either red/green.

5. Request will have the status you selected in step 4 and delete the request if turned to red.

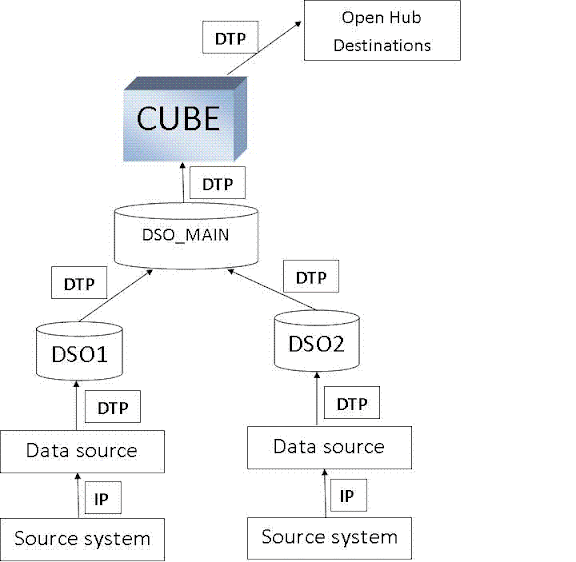
Data Transfer Process (DTP) over Info Package (IP) in SAP BI 7.0
DTP
(Data Transfer Process):
Data
transfer process (DTP) loads data within BI from one object to another object
with respect to transformations and filters. In short, DTP determines how data
is transferred between two persistent objects. It is used to load the data from
PSA to data target (CUBE or DSO or Info Object or External systems) thus, it
replaced the data mart interface and the Info Package. In BI 7.0 Info Package
pulls the data only till data source/PSA from source system, thereafter we need
to create the transformation and DTP to pull the data further in BI system and
to external systems.
IP
(Info Package):
The
Info Package is an entry point for SAP BI to request data from a source system.
Info Packages are tools for organizing data requests that are extracted from the
source system and are loaded into the BW system. In short, loading data into the
BW is accomplished using Info Packages.
Where
DTP comes in Data Flow:
DTP
can be used to load the data in the following situations:
1)
Loading data from DSO to DSO/CUBE, CUBE to CUBE
2)
Real time Data Acquisition
3)
For Data Direct Accessing.
4)
Loading data from BI to External systems (for example Open Hub
Destinations)
Advantages
of DTP:
1)
Delta Management
2)
Handling duplicate records
3)
Filters
4)
Parallel processing
5)
Error Handling
6)
Debugging
1)
Delta Management:
i)
DTP follows one to one mechanism, i.e. We have to create one DTP for each data
target, whereas IP loads to all data targets at once.
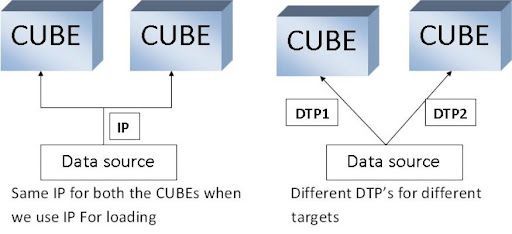
Advantage:
Let's
take an example where we are loading delta data using IP to 5 data targets. The
data was successfully loaded into 4 targets but failed in 1 target.
In
this case we have to delete the request from all 5 targets and need to re-load
the IP to load the data.
If
we use DTP (one to one mechanism), we need to just delete the request from
failed targets and re-load to the failed target, which is very easier than
loading to all 5 targets once again.
I)
One DTP can be used for Full and Delta loads, whereas in IP we have to create
different Info Packages for Full and Delta loads,
iii)
No Full Repair/Repair full request concept in DTP as it has one to one delta
mechanism.
Note: Data
Mart and Delta for DTP is maintained in table RSMDATASTATE.
In
Table RSMDATASTATE
i)
Field DMALL is used to keep track of Delta. It increases when Delta
completes
ii)
Field DMEXIST is used to prevent deletion of Source request.
Deleting
data request deletes the entry in table RSSTATMANREQMAP which keep track of data
marts
2)
Handling duplicate records:
While
we perform attributes or text loading, we will get the records with same key
fields. Sometimes based on the properties of the fields we have to load this
records to the target (Info object).This can be easily achieved by DTP.
We
have to set the option “Handle Duplicate Record Keys” indicator in update tab of
DTP to get this feature enabled.
3)
Filters:
DTP
filter's the data based on Semantic Key which is not possible on IP. We can use
filters between DSO and CUBE also.
4)
Parallel processing:
The
request of a standard DTP should always be processed in as many parallel
processes as possible. There are 3 processing modes for background processing of
standard DTPs.
i) Parallel extraction and processing (transformation
and update)
The data packages are extracted and processed in parallel, i.e. The parallel
process is derived from the main process for each data package.
ii) Serial extraction, immediate parallel processing
The data packages are extracted sequentially and processed in parallel, i.e.
The main process extracts the data packages sequentially and derives a process
that processes the data for each data package.
iii) Serial
extraction and processing of the source packages
The data packages are extracted and processed sequentially.
We
can change this setting in the execution tab of DTP.
The
maximum number of background parallel processes we can set for a DTP is
99.
5)
Error Handling:
The
error DTP concept is introduced to handle the error records in DTP. While
loading the data using DTP, error records will move to the error stack and the
correct records will load to the target. We can edit this error records in error
stack and load to the target using Error DTP, which is not possible in IP.

6)
Debugging:
Simulating
the data update and debugging helps us to analyze an incorrect DTP request. In
this way we can also simulate a transformation prior to the actual data transfer
if we would like to check whether it provides the desired results.
We
can define break points for debugging by choosing change break points, which
was not available in Info Package.
Debugging
can be done in 2 ways
i) Simple Simulation
ii) Expert Mode
1. Introduction to DTP
The
data transfer is the process to transfer the data within the BW data warehouse.
It is used to update data from one data target to another data target. It also
enables error handling of records.
2. Loading data from an existing 3.5 flow to 7.0 objects
While
loading the data to an exiting 3.5 flow e.g., DSO to Cube (Delta load), after
the completion of the data load the data mart status is set. Hence if we create
a new cube which needs to get delta from this cube using BW7 development of
DTP's and transformation, it is not able to recognize the deltas.
To
handle this situation we have a setting in the source DSO info package to show
that the DTP load is active. After making this setting the cube will be able to
detect the delta in the base DSO even after data mart status being set,

This
setting is very useful, when we plan to integrate 2 flows one of BW 3.x and BW
7.0.
3. Error Handling using DTP
Any
error records are updated in error stack. Error DTP is then used to update the
data to the subsequent data targets.

3.1. Options in error handling
a.
Deactivated
Using
this option error stack is not enabled at all. Hence for any failed records no
data is written to the error stack. Thus if the data load fails, all the data
needs to be reloaded again.
b.
No update, no reporting
If
there is erroneous/incorrect record and we have this option enabled in the DTP,
the load stops there with no data written to the error stack. Also this request
will not be available for reporting. Correction would mean reloading the entire
data again.
c.
Valid Records Update, No reporting (Request Red)
Using
this option all correct data is loaded to the cubes and incorrect data to the
error stack. The data will not be available for reporting until the erroneous
records are updated and QM status is manually set to green. The erroneous
records can be updated using the error DTP.
d.
Valid Records Updated, Reporting Possible (Request Green)
Using
this option all correct data is loaded to the cubes and incorrect data to the
error stack. The data will be available for reporting and process chains
continue with the next steps. The erroneous records can be updated using the
error DTP.
3.2. How to find the error Stack Table?
To
locate the error stack table navigate as shown below:
Extras
-> Settings for Error Stack
Here
the table name gives the name of the table where the error records reside.
4. Temporary data storage using DTP
In
DTP we can define if we want to store the data temporarily at any stage during
the process of data load. It could be before extraction, after transformation
etc. It helps is easier analysis of the data. So, it also becomes easier to
start the failed load process after this.
To
locate this setting , we navigate as shown below:
Goto
-> Settings for DTP Temporary Storage
Here
we can view the temporary storage settings.
5. Extraction Modes
The
data can be loaded to the data target via two extraction modes.
- Full -> Extraction of data that is requested
- Delta Mode - > Extraction of data new data
Each
of these is explained below.
5.1. Full
It
behaves in the same way as info package does. PSA should be deleted every time
before using this option.
The
following sources can have only Full load option.
1.
Info Object
2.
Info Set
3.
Direct Update DSO
5.2. Delta
No
initialization is required to have a DTP work with delta mechanism. When the DTP
is executed with this option for the first time, it brings all the data from the
source and also sets the target in such way that it is initialized.
In
the scenarios, where we want to load only the new data, the option
No data transfer; delta status in source: fetched as processing mode in the execute tab of the DTP works in the same way as the init in the info package.
No data transfer; delta status in source: fetched as processing mode in the execute tab of the DTP works in the same way as the init in the info package.
6. Processing Mode
These
modes detail the steps that are carried out during DTP execution (e.g.
Extraction, transformation, transfer etc). Processing mode also depends on the
type of source.
The
various types of processing modes are shown below:
a.
Serial extraction, immediate parallel processing (asynchronous processing)
This
option is most used in background processing when used in process chains. It
processes the data packages in parallel.
b.
Serial in dialog process (for debugging) (synchronous processing)
This
option is used if we want to execute the DTP in dialog process and this is
primarily used for debugging.
c.
No data transfer; delta status in source: fetched
This
option behaves exactly in the same way as explained above.
6.1. Parameters with Delta Mode
a.
Only Get Delta Once_:_ This is best used in the scenario where we want to use
the snapshot data. E.g. Budget data, if we want to overwrite the existing
budgets in the cube, this setting will enable us to delete the existing request
from the cube and overwrite with the new request with the same selections.
If
we use this setting in the process chains, we need to use the delete overlapping
request option along with this.
b.
Get data Request by Request: If we use this option a scenario of backlog might
be created. If 5 requests of the data have been loaded to the PSA, when DTP is
executed with the same setting, it just brings the oldest request. This is not
advisable to be used in the process chains as it does not load the current
data.
c.
Retrieve until No More New Data_:_ This option is added to the DTP's to enable
the DTP's to get all the requests in the source until all the requests are
loaded. E.g. if we have 3 requests in the source, disabling this setting will
force only one request to get transferred to the target, whereas by enabling
this setting we will be able to see 3 separate requests in the target. This
option becomes very useful when the data package cannot handle too many
records.
7. Significance of Semantic Groups
This
defines the key fields of the data package when read from the source. The same
keys applies to the error stack as well e.g. while doing the parallel processing
of the time dependant master data, DTP may contain different settings from the
DataSources.
8. Performance Optimization using DTP
a.
Number of parallel process
We
can define the number of processes to be used in the DTP by navigating as shown
below:
If
the number of processes is equal to 1, is serial processing, else
parallel.
b.
Data Package Size
The
default size of the data package is 50000. This can be changed depending on the
size of the records.
c.
Do not load too large DTP Requests at one go.
This
can be achieved by enabling the setting "Get all new data request by request "as
detailed above. This facilitates in reduction of the size of each DTP, hence
improving the performance.
d.
If we are planning to use DTP filters while loading the data from data source,
small data packages can be avoided.
In
such scenarios it is best to redefine the semantic keys.
e.
If DSO is the source, extraction of data before doing first delta or while full
extraction from the active data table is not advisable.
Full
load can be best read from active data table, owing to less number of
records.
f.
If we are planning to use Info Cubes as the source to load data, its best to use
the option use extraction from aggregates.
If
this option is enabled, and if the required data exists in the aggregates, it
reads the data from the aggregates before reading it from F table or E table
directly.
9. Handling Duplicate Data Records
This
functionality is used to handle the duplicate data records which loading the
data to the attributes or texts.
This
option is not set by default.
In
handles the data as shown below:
- Time Independent Objects
The
data of the last record resides as it keeps on overwriting the data.
- Time Dependant Objects
In
this scenario, it creates various entries of the same object with different
validity periods.
 in SAP Netweaver BW (BI)")
In this example, I have created a custom data model that shows the related serial number(s) for a given delivery number, item, and material number. When loading the infocube, I want to ensure that all serial numbers for a given delivery number, item, and material are contained within the same data transfer package (DTP).
However, the settings for Semantic Groups are unavailable by default (as seen below)
")
Fig. 1 Semantic Group is disabled by
default.
Navigate to the ‘Update’ tab and click on the ‘Error Handling’ window to see the four options:
- Deactivated
- No Update, No Reporting (default)
- Valid Records Update, No Reporting (Request Red)
- Valid Records Update, Reporting Possible (Request Green)

Fig. 2 Default Error Stack Setting
Selecting the option “Valid Records Update, No Reporting (Request Red)” will leave the error records in the error stack and set the QM status for this request to Red. Now that I have chosen my error handing option, I can set Semantic Group.

Fig 3. Custom Error Package
Setting
Click on the ‘Semantic Group’ button and confirm that a ‘Selection of Key Fields for Error Stack’ window appears.
Now, you can determine how the system groups the records when reading from the data source. Unselect the unnecessary fields. Leave the key fields for your logical group as checked.

Fig. 4 Semantic Grouping is now
available
Recently, I had to implement my own version of the obsolete ABAP construct “ON CHANGE OF” event block and found the following to be true: While records may be grouped in a DTP as shown above, you cannot assume that they are sorted by the DSO keys as defined.
You will need to perform an explicit “SORT” on the source/result package as required by your start/end routine logic if you are performing custom comparison operations. Be diligent! =D
Great blog !!
ReplyDeleteAwesome. Realy cool stuff .