Use
You use partitioning to split the total dataset for an InfoProvider into several, smaller, physically independent and redundancy-free units. This separation improves system performance when you analyze data delete data from the InfoProvider.
Prerequisites
You can only partition a dataset using one of the two partitioning criteria ‘calendar month’ (0CALMONTH) or ‘fiscal year/period (0FISCPER). At least one of the two InfoObjects must be contained in the InfoProvider.
If you want to partition an InfoCube using the fiscal year/period (0FISCPER) characteristic, you have to set the fiscal year variant characteristic to constant.
There are 2 types of partition.1. Physical Partition
2. Logical Partition
This allocation of physical memory will differ based on the type of the data target.
For example:
DSO is a flat-table and its capacity is entirely based on the total capacity of the database ideally.
Info-cube is a multi-dimensional structure and its capacity is based on the number of dataload requests it has or indirectly number of the data partitions happened at the database level because of the data-loads happening or happened to the respective info-cubes.
As the number of the dataload requests increases, the respective partitions at the database level also increases. This limit is database dependent.
Example, for SQL data base, it is 1000 and for DB2 it is 1200 approx based on their respective service packs installed.
Throughout this document I have consider the Microsoft’s SQL database for the explanation, i.e., whose data partition limit is equal to 1000
Illustration of partition of the database w.r.t the Infocube data loads
As mentioned above the database partition of the database for the Infocube happens based on the number of dataload requests that cubes has. I.e. one new dataload request into the respective cubes creates a partition at the database multiply by the number of dataloads happened into it till date. You use partitioning to split the total dataset for an InfoProvider into several, smaller, physically independent and redundancy-free units. This separation improves system performance when you analyze data delete data from the InfoProvider.
Prerequisites
You can only partition a dataset using one of the two partitioning criteria ‘calendar month’ (0CALMONTH) or ‘fiscal year/period (0FISCPER). At least one of the two InfoObjects must be contained in the InfoProvider.
If you want to partition an InfoCube using the fiscal year/period (0FISCPER) characteristic, you have to set the fiscal year variant characteristic to constant.
There are 2 types of partition.1. Physical Partition
2. Logical Partition
1. Physical Partition:
Introduction As we all know that the SAP BI system will have a backend database to store the data records which comes into the system through the various data sources like R3, Standalone Legacy Systems etc.,. Whenever a data target is created in the SAP BI/BW system, some portion of the database memory will be allocated to its (data targets) in-terms of physical address.This allocation of physical memory will differ based on the type of the data target.
For example:
DSO is a flat-table and its capacity is entirely based on the total capacity of the database ideally.
Info-cube is a multi-dimensional structure and its capacity is based on the number of dataload requests it has or indirectly number of the data partitions happened at the database level because of the data-loads happening or happened to the respective info-cubes.
As the number of the dataload requests increases, the respective partitions at the database level also increases. This limit is database dependent.
Example, for SQL data base, it is 1000 and for DB2 it is 1200 approx based on their respective service packs installed.
Throughout this document I have consider the Microsoft’s SQL database for the explanation, i.e., whose data partition limit is equal to 1000
Illustration of partition of the database w.r.t the Infocube data loads

As the number of the dataload requests increases, the number of the data-base partitions w.r.t info-cube also increases since both are directly proportional. Once this reaches the limit of the database used, no more data loads can happen for the respective Infocube (data-target) according to the property of the database.
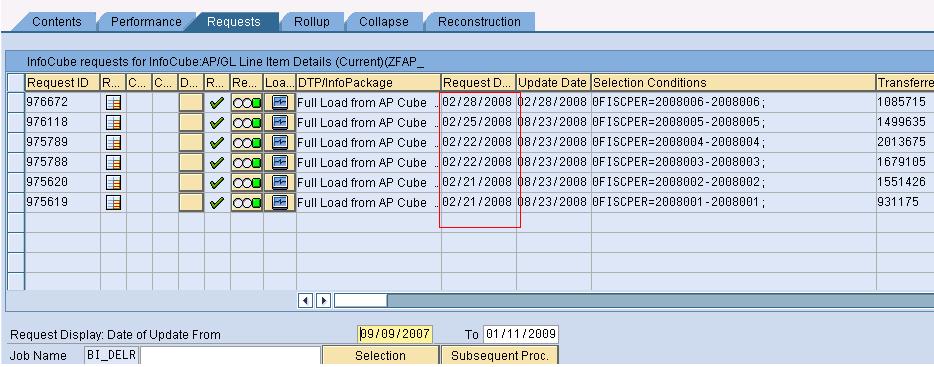
Data base partition limit calculation In the above considered cube, the dataload is happening from 21st Feb of 2008 as depicted in the figure (shown above). Assumptions: Dataloads are happening every day. Hence in a non-leap year, ideally 365 data loads =
365 data partitions at the database level. [SQL database is considered whose upper partition limit is 1000.]
Therefore till Nov 18, 2010 (313 days of 2008+ 365 days of 2009 + 322 days of 2010) the dataloads will happen successfully to the considered Infocubes, later to this the loads will fail as there will be no physical space to store the records.
And also the SAP’s standard table "
RSMSSPARTMON " provides the details like the number of partitions happened at the database level w.r.t to the data targets(info-cube), these details can be used to get the accurate result w.r.t Info-cubes.
How to avoid the database partition limit consequences One method is to use the logical partition of the data-targets which includes the backup of the data into some other data-targets from the actual ones and deleting the respective data (which is replaced to the other cubes) from the actual data-targets and compression of the actual data-targets dataload request whose data is replaced from the actual to the another newly created (copied) data-targets.
This compression activity will delete the data-load request details from the database level and hence indirectly reducing the number of partitions at the data-base level previously had happened w.r.t individual data-targets.
Steps to compress the Infocube (data)

Select the required request ID or range of request ids for which the compression has to be carried, and then schedule the process.
This will delete the respective data-load request id/ids and reduce the number of partitions w.r.t the infocube/data-target created at the database level, thus increases the number of available partitions. [This compression activity can be controlled to the required level like by giving the individual request numbers or the range of the requests as depicted in the above screen shot.] The compression of data-targets, for e.g. for info-cubes, will make the data deletion process using the data-load request id/ids impossible by moving the contents of fact table into E table, but this will not have any impact on the abovementioned logical process as the compression is done for the request/requests whose data is already replaced from the actual target to the other target and deleted from the actual target into which the data loads will be happening on regular basis.
2. Logical Partition:
When you activate the InfoProvider, the system creates the table on the database with one of the number of partitions corresponding to the value range. You can set the value range yourself.
Choose the partitioning criterion 0CALMONTH and determine the value range
From 01.1998
To 12.2003
6 years x 12 months + 2 = 74 partitions are created (2 partitions for values that lay outside of the range, meaning < 01.1998 or >12.2003).
You can also determine the maximum number of partitions created on the database for this table.
Choose the partitioning criterion 0CALMONTH and determine the value range
From 01.1998
To 12.2003
Choose 30 as the maximum number of partitions.
Resulting from the value range: 6 years x 12 calendar months + 2 marginal partitions (up to 01.1998, from 12.2003) = 74 single values.
The system groups three months together at a time in a partition (meaning that a partition corresponds to exactly one quarter); in this way, 6 years x 4 partitions/year + 2 marginal partitions = 26 partitions created on the database.
The performance gain is only achieved for the partitioned InfoProvider if the time characteristics of the InfoProvider are consistent. This means that with a partition using 0CALMONTH, all values of the 0CAL x characteristics of a data record have to match.
In the following example, only record 1 is consistent. Records 2 and 3 are not consistent:

Activities
In InfoProvider maintenance, choose Extras DB Performance -Partitioning and specify the value range. Where necessary, limit the maximum number of partitions.
Partitioning InfoCubes Using the Characteristic 0FISCPER:
You can partition InfoCubes using two characteristics – calendar month (0CALMONTH) and fiscal year/period (0FISCPER). The special feature of the fiscal year/period characteristic (0FISCPER) being compounded with the fiscal year variant (0FISCVARNT) means that you have to use a special procedure when you partition an InfoCube using 0FISCPER.
Prerequisites
When partitioning using 0FISCPER values, values are calculated within the partitioning interval that you specified in the InfoCube maintenance. To do this, the value for 0FISCVARNT must be known at the time of partitioning; it must be set to constant.
Procedure
1 The InfoCube maintenance is displayed. Set the value for the 0FISCVARNT characteristic to constant. Carry out the following steps:
a. Choose the Time Characteristics tab page.
b. In the context menu of the dimension folder, choose Object specific InfoObject properties.
c. Specify a constant for the characteristic 0FISCVARNT. Choose Continue.
2. Choose Extras ® DB Performance ® Partitioning. The Determine Partitioning Conditions dialog box appears. You can now select the 0FISCPER characteristic under Slctn. Choose Continue.
3. The Value Range (Partitioning Condition) dialog box appears. Enter the required data.
Data Flow Summary:

contains consolidated data
is optimized for reading
might be huge
is partitioned by the user
cannot be partitioned once InfoCube contains data!
F fact table
contains data on request level
is optimized for writing / deleting
should be small
is partitioned by the system



PSA PARTITIONING


Provides for faster data load performance
Array inserts are possible
Insert occurs into smaller database object
Ability to easily maintain PSA as a temporary data staging area
Deletion of requests from the PSA can be handled as a drop partition SQL command
Deleting PSA records:
Select request to be deleted - records from request in PSA are flagged for deletion
When all records have been flagged - PSA partition is dropped
Threshold is not a hard limit
Thresholds will normally be exceeded by data loads
Threshold setting exists as a way of determining if a new partition is required when records from a new data load are about to be added
Records from one InfoPackage will never “span” more than one partition
A partition could become very large if a data load volume is very large
A PSA partition can hold records from several InfoPackages Repartitioning
Thresholds will normally be exceeded by data loads
Threshold setting exists as a way of determining if a new partition is required when records from a new data load are about to be added
Records from one InfoPackage will never “span” more than one partition
A partition could become very large if a data load volume is very large
A PSA partition can hold records from several InfoPackages Repartitioning
Repartitioning
Use
Repartitioning can be useful if you have already loaded data to your InfoCube, and:
● You did not partition the InfoCube when you created it.
● You loaded more data into your InfoCube than you had planned when you partitioned it.
● You did not choose a long enough period of time for partitioning.
● Some partitions contain no data or little data due to data archiving over a period of time.
No comments:
Post a Comment